LMスタジオを使用したカスタムLLM構築
LMスタジオのインストール
- https://lmstudio.ai/よりLMスタジオをインストールします。
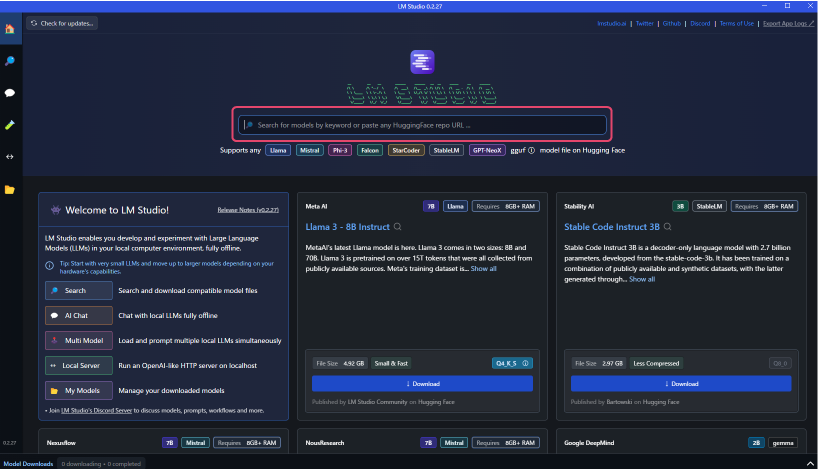
カスタムLLMのダウンロード
- LMスタジオを起動させ、画面中央にある検索バーからLLMを検索します。
ここでは例として「DataPilot-ArrowPro-7B-KUJIRA-gguf」を使用してLLMを構築していきます。
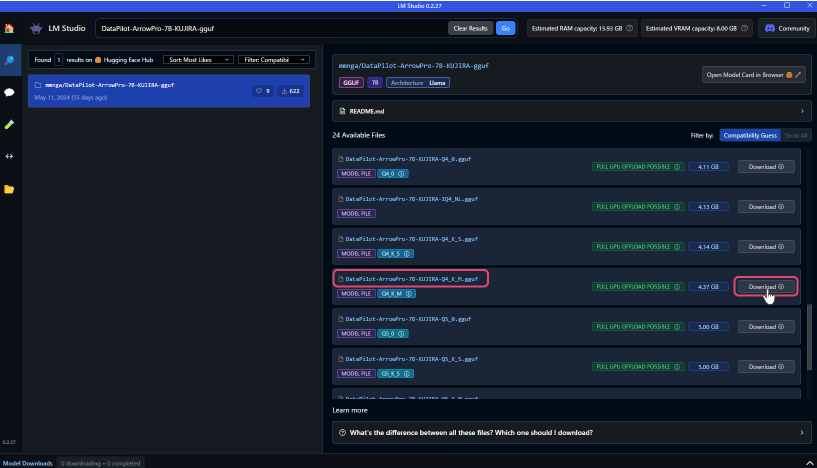
- 検索をすると画面右側に該当する検索候補が複数表示されます。
目的のLLMを見つけたら「Download」をクリックしてモデルのダウンロードを開始します。
カスタムLLMの立ち上げ
- ダウンロード完了後、左サイドバー内にある「↔」ボタンをクリックして画面のモードを変更します。
画面上部にある「Select a model to load」をクリックすると、プルダウンでダウンロード済みのLLMが一覧で表示されるので、ダウンロードしたモデルを選択します。
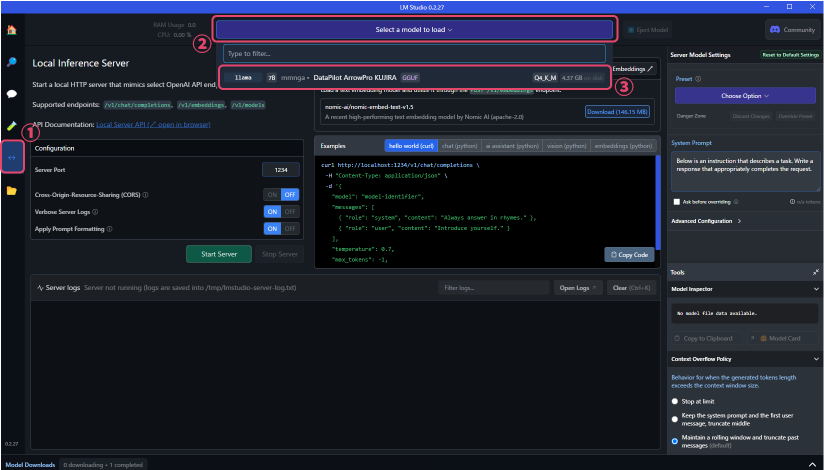
- 画面中央付近にailia DX Insight内の設定で使用するカスタムLLMのURLが表示されます。(通常はlocalhost:1234に設定されます)
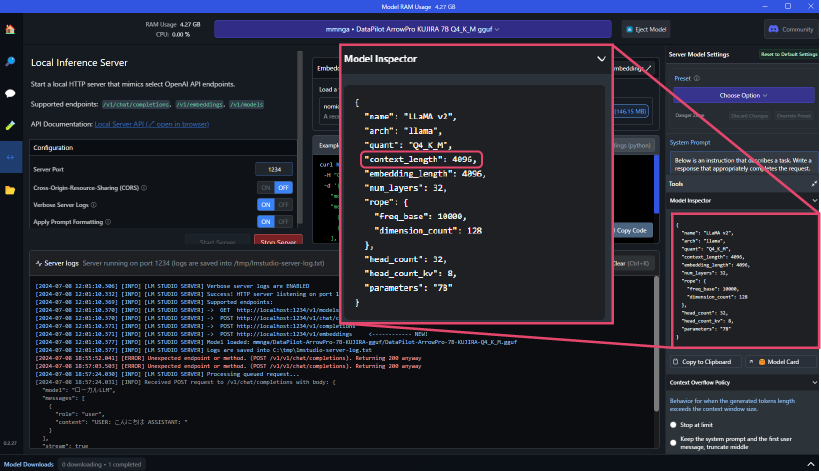
- 画面右側「Model Inspector」内に記載の
context_lengthの数値がailia DX Insight内の設定で使用する「最大トークン数」となります。
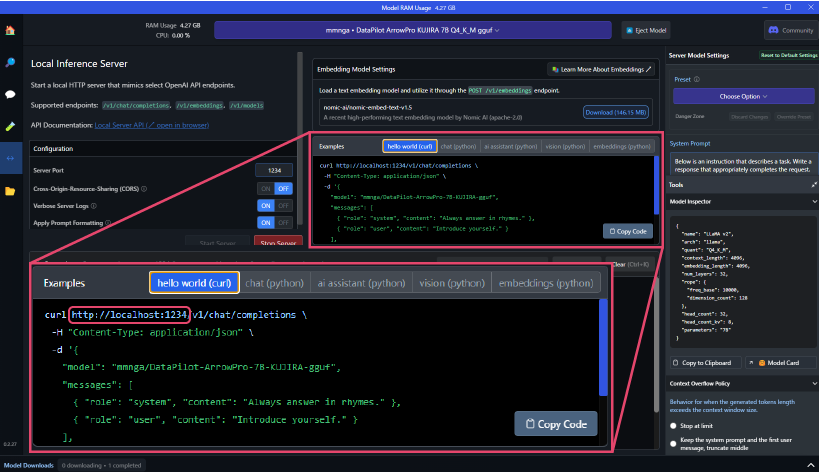
- 画面中央付近にailia DX Insight内の設定で使用するカスタムLLMのURLが表示されます。(通常はlocalhost:1234に設定されます)
aillia DX InsightでカスタムLLMの登録
詳しい設定画面の呼び出し方はこちらをご参照ください。
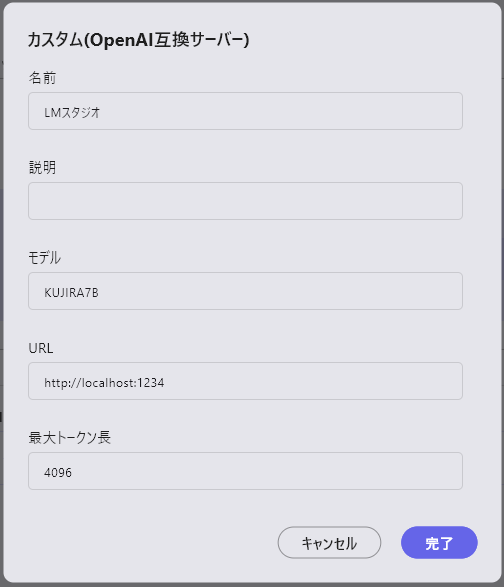
- 名前:使用するLLMの名称 (UI表示にのみ使用するため何でも構わない)
- 説明:必要に応じてメモとして使用
- モデル:ダウンロードしたモデルの名称
- URL(*):カスタムLLMの立ち上げで表示されたURL(通常はlocalhost:1234に設定されます)
- 最大トークン長:カスタムLLMの立ち上げで表示された
context_lengthの数値
(*)未記入の場合、HTTPの接続エラーになります。
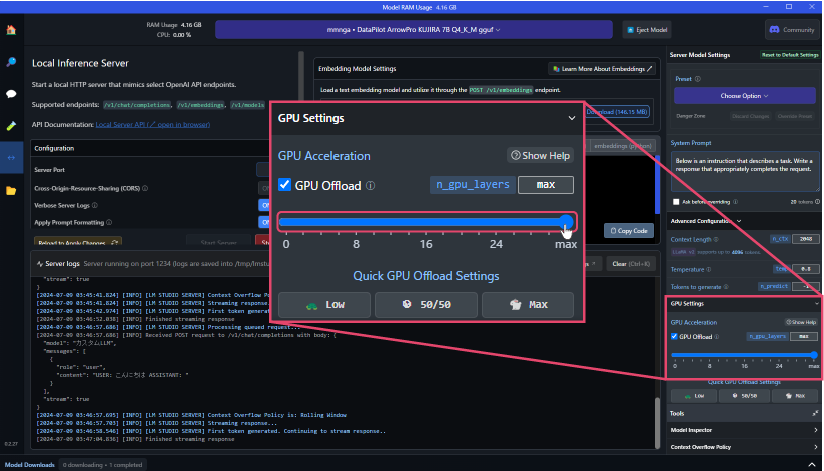
ローカルLLMの処理速度を向上させる方法
画面右側の「Advanced Configration」内にある「GPU Settings」のパラメータ値を変更することでGPUメモリを使用する割合を変更することができます。
GPU Offloadパラメータを最大に設定すると、GPUメモリを使用した高速処理をおこなうことができます。