Recommended LLMs by Our Company
We will introduce a list of recommended LLMs for PCs with GPU memory of less than 8GB to 8GB, classified by LLM parameter size into ultra-small, small, and medium (or larger).
Some models offer multiple variants with different parameter counts, which can be identified by the numbers marked with B (Billion) within each model name. If you have extra GPU memory, you can search for and use higher models from sources like LM Studio.
Please choose a model suited to your usage purpose and PC environment based on parameter size, RAM usage, and features. (The RAM usage listed may vary depending on the quantization method used).
Ultra-Small (0.5B to 4B)
Qwen/Qwen2.5-0.5B-Instruct-GGUF (RAM usage 1.18GB or more)
Qwen/Qwen2.5-1.5B-Instruct-GGUF (RAM usage 1.27GB or more)
Qwen/Qwen2.5-3B-Instruct-GGUF (RAM usage 1.44GB or more)
Features: These are LLMs provided by Alibaba Cloud, utilizing training data in 27 languages in addition to English and Chinese, and demonstrating high performance in benchmarks like natural language understanding, knowledge acquisition, coding, mathematics, and multilingual support. Being an extremely small model at 0.5B, it has limited knowledge but is optimal for use on low-spec PCs. In Qwen2.5, performance in various specialized areas has been significantly enhanced, evolving into a language model capable of handling diverse tasks.
DeepSeek-R1-Distill-Qwen-1.5B-GGUF (RAM usage 1.37GB or more)
Features: This is a large-scale language model developed by DeepSeek in China, specialized for inference ability. It demonstrates high performance comparable to major models in key benchmarks like inference tasks, math problems, coding, long text inference, and creative writing. "DeepSeek-R1-Distill-Qwen-14B/32B-Japanese," which has undergone additional training with Japanese data by CyberAgent, has been released.
TinySwallow-1.5B-Instruct-GGUF (RAM usage 1.13GB or more)
Features: Announced by "Sakana AI," an AI company based in Japan, this is a small-scale Japanese language model. Developed utilizing a new knowledge distillation method called TAID (Time Adaptive Interpolation Distillation), it demonstrates the highest performance in benchmark tests evaluating Japanese functions among models of similar scale. It is lightweight enough to operate on smartphones, enabling operation in resource-constrained environments.
lmstudio-community/gemma-2-9b-it-GGUF (RAM usage 2.32GB to 9.15GB)
bartowski/gemma-2-2b-it-GGUF (RAM usage 1.79 to 3.05GB)
Features: Built using the same architecture as Google’s cutting-edge AI model, Gemini, Gemma2 delivers high performance despite being lightweight. The 27 billion parameter model, in particular, achieves top performance in its size class, rivaling models more than twice the size, while the 9 billion parameter model also shows excellent performance surpassing other open models of the same size. Additionally, the 2 billion parameter model delivers class-leading performance relative to its size, making it suitable for use on notebooks, etc.
microsoft/Phi-3-mini-4k-instruct-gguf (RAM usage around 2.99GB)
QuantFactory/Phi-3-mini-128k-instruct-GGUF (RAM usage 2.08 to 4.54GB)
Features: LLM provided by Microsoft, it has comparable performance to models more than twice its size despite being a very small model with 3.8B (3.8 billion parameters). Currently, two models supporting 4K tokens and 128K tokens have been released.
Small (7B to 9B)
Qwen/Qwen2.5-7B-Instruct-1M-GGUF (RAM usage 1.97GB or more)
Features: These are LLMs provided by Alibaba Cloud. Utilizing training data in 27 languages in addition to English and Chinese, they demonstrate high performance in benchmarks like natural language understanding, knowledge acquisition, coding, mathematics, and multilingual support. Qwen2.5 has evolved into a language model capable of handling diverse tasks by significantly enhancing performance in various specialized areas. Qwen2.5-1M is developed based on Qwen2.5-Turbo, making it possible to process up to 1 million tokens of context.
Qwen/Qwen2.5-7B-Instruct-GGUF (RAM usage 1.14GB or more)
Features: These are LLMs provided by Alibaba Cloud. Utilizing training data in 27 languages in addition to English and Chinese, they demonstrate high performance in benchmarks like natural language understanding, knowledge acquisition, coding, mathematics, and multilingual support. Qwen2.5 has evolved into a language model capable of handling diverse tasks by significantly enhancing performance in various specialized areas.
DeepSeek-R1-Distill-Qwen-7B-GGUF (RAM usage 2.23GB or more)
DeepSeek-R1-Distill-Llama-8B-GGUF (RAM usage 2.04GB or more)
Features: A large-scale language model developed by DeepSeek in China, specialized for inference ability, demonstrating high performance comparable to major models in key benchmarks like inference tasks, math problems, coding, long text inference, and creative writing. "DeepSeek-R1-Distill-Qwen-14B/32B-Japanese," which has undergone additional training with Japanese data by CyberAgent, has been released.
mmnga/umiyuki-Umievo-itr012-Gleipnir-7B-gguf (RAM usage 2.33 to 6.34GB)
Features: A high-performing Japanese LLM completed by integrating four models: Japanese-Starling-ChatV-7B, Ninja-v1-RP-expressive-v2, Vecteus-v1, and Japanese-Chat-Umievo-itr004-7b4.
mmnga/DataPilot-ArrowPro-7B-KUJIRA-gguf (RAM usage 2.26 to 3.49GB)
mmnga/ArrowPro-7B-KillerWhale-gguf (RAM usage 2.26 to 6.24GB)
Features: Based on the open-source LLM "NTQAI/chatntq-ja-7b-v1.0," this model was developed for use in AI applications like virtual YouTubers (AI Tubers) and AI assistants, demonstrating high performance in Japanese with high-quality conversations being highly regarded. "ArrowPro-7B-KillerWhale" is positioned as an enhanced version of "DataPilot/ArrowPro-7B-KUJIRA."
mmnga/Llama-3.1-8B-Instruct-gguf (RAM usage 2.26 to 5.79GB)
Features: The most advanced and high-performing LLM from Meta, Llama 3.1 supports advanced use cases like long-text summarization, multilingual conversation agents, coding assistance, etc., with a 128K context length, cutting-edge tool usage, and enhanced inference capabilities.
mmnga/Llama-3-ELYZA-JP-8B-gguf (RAM usage 2.73 to 8.75GB)
Features: Designed by ELYZA, an AI company from UTokyo Matsuo Lab, this LLM is specialized for Japanese. Based on Meta's Llama 3 8B-Instruct, it is trained using large Japanese datasets, becoming well-acquainted with Japanese grammar, vocabulary, and cultural background, enabling it to accurately understand unique Japanese expressions and nuances while generating sophisticated Japanese text.
Medium (or Larger)
Qwen/Qwen2.5-14B-Instruct-1M-GGUF
Features: These are LLMs provided by Alibaba Cloud. Utilizing training data in 27 languages in addition to English and Chinese, they demonstrate high performance in benchmarks like natural language understanding, knowledge acquisition, coding, mathematics, and multilingual support. Qwen2.5 has evolved into a language model capable of handling diverse tasks by significantly enhancing performance in various specialized areas. Qwen2.5-1M is developed based on Qwen2.5-Turbo, making it possible to process up to 1 million tokens of context.
Qwen/Qwen2.5-14B-Instruct-GGUF
Qwen/Qwen2.5-32B-Instruct-GGUF
Qwen/Qwen2.5-72B-Instruct-GGUF
Features: These are LLMs provided by Alibaba Cloud. Utilizing training data in 27 languages in addition to English and Chinese, they demonstrate high performance in benchmarks like natural language understanding, knowledge acquisition, coding, mathematics, and multilingual support. Qwen2.5 has evolved into a language model capable of handling diverse tasks by significantly enhancing performance in various specialized areas.
DeepSeek-R1-Distill-Qwen-14B-GGUF
DeepSeek-R1-Distill-Qwen-32B-GGUF
DeepSeek-R1-Distill-Llama-70B-GGUF
Features: These are large-scale language models developed by DeepSeek in China, specialized for inference ability. They demonstrate high performance comparable to major models in key benchmarks like inference tasks, math problems, coding, long text inference, and creative writing. "DeepSeek-R1-Distill-Qwen-14B/32B-Japanese," which has undergone additional training with Japanese data by CyberAgent, has been released.
mmnga/ELYZA-japanese-Llama-2-13b-fast-instruct-gguf (RAM usage 6.13 to 14.31GB)
Features: Designed by ELYZA, an AI company from UTokyo Matsuo Lab, this LLM is specialized for Japanese. Based on Meta's Llama 2 13B, it is trained using large Japanese datasets, becoming well-acquainted with Japanese grammar, vocabulary, and cultural background, enabling it to accurately understand unique Japanese expressions and nuances while generating sophisticated Japanese text.
Note: A new ELYZA model based on Llama3 is expected to be released soon (as of June 27, 2024).
lmstudio-community/gemma-2-27b-it-GGUF (RAM usage 8 to 29.65GB)
Features: Gemma2 is built using the same architecture as Google’s cutting-edge AI model, Gemini, delivering high performance despite being lightweight. The 27 billion parameter model achieves top performance in its size class, rivaling models more than twice the size, while the 9 billion parameter model also shows excellent performance surpassing other open models of the same size.
andrewcanis/c4ai-command-r-v01-GGUF (RAM usage 8 to 10.27GB)
Features: Command-R is an LLM created by CohereForAI, containing 35B (35 billion) parameters. This model excels at generating or summarizing text, or answering questions based on large amounts of information.
pmysl/c4ai-command-r-plus-GGUF(RAM usage 8~212.71GB)
Features: Command R+ is an enhanced version of Command R, an LLM with 104B (104 billion) parameters. This model is designed to deliver excellent performance for enterprises, and is open source and available for anyone to use, yet it achieves performance approaching GPT-4 Turbo. It also supports long context sentences up to 128K.
(Additional Information) Regarding the use of command-r-v01/Command R Plus: command-r-v01/Command R Plus is an LLM that allows for the modification and distribution of models for non-commercial use. Please note that for commercial (business) use, you will need to use the provider's paid API service. You can obtain the paid API from the website on the right (https://cohere.com/command)
Qwen/Qwen2-72B-Instruct-GGUF(RAM usage 8~148.98GB)
Features: This is an LLM provided by Alibaba Cloud. Utilizing training data in 27 languages in addition to English and Chinese, it has demonstrated high performance in benchmarks such as natural language understanding, knowledge acquisition, coding, mathematics, and multilingual support. The 7B and 72B models support long-form contexts of up to 128K tokens.
mmnga/Llama-3.1-70B-Instruct-gguf(RAM usage 7.66~9.07GB)
Features: This is Meta's most advanced and performant LLM to date. With a 128K context length, cutting-edge tooling, and enhanced reasoning capabilities, Llama 3.1 supports advanced use cases such as long-text summarization, multilingual conversational agents, and coding assistance.
Supplement about our recommended LLMs
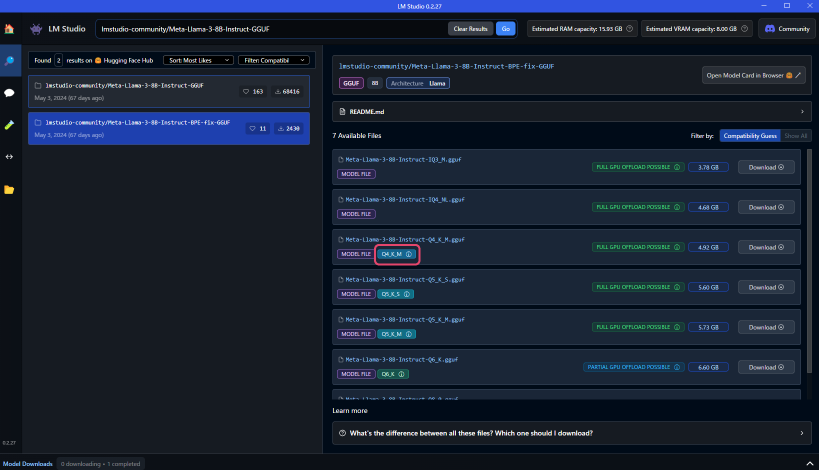
When searching for recommended LLMs on LM Studio, many models are expected to appear.
We recommend using models with a 4-bit quantization that offer excellent balance between size and performance.
Specifically, models with the notation Q4_K_M or similar quantization.
When Running LM Studio on a Linux Server
If you encounter the following error when trying to connect from ailia DX insight while running LM Studio on a Linux server, it might be due to the server's firewall settings prohibiting access to the port.
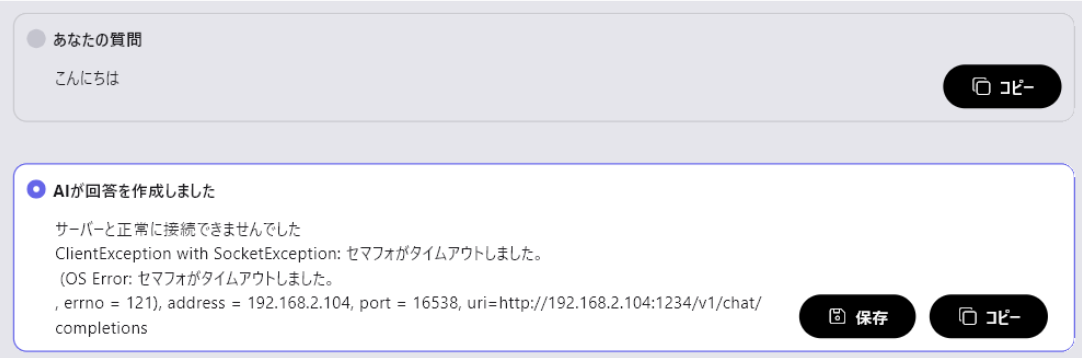
Please allow access to the port with the command
sudo ufw allow 1234/tcp
(replace "1234" with the number set in LM Studio).