Local LLM Configuration
By using the GGUF-compressed LLM model, you can easily connect to a local LLM only within ailia DX Insight.
The PC requirements to run a local LLM are as follows:
For Windows
- Requirements for the 2b model
GPU Execution: GPU with 4GB or more VRAM supporting Vulkan 1.1 or later CPU Execution: CPU supporting AVX2, with 8GB or more memory - Requirements for the 9b model
GPU Execution: GPU with 6GB or more VRAM supporting Vulkan 1.1 or later CPU Execution: CPU supporting AVX2, with 8GB or more memory
For MacOS
- Requirements for the 2b model
Apple Silicon with 8GB or more memory - Requirements for the 9b model
Apple Silicon with 16GB or more memory
Building a Local LLM within ailia DX Insight
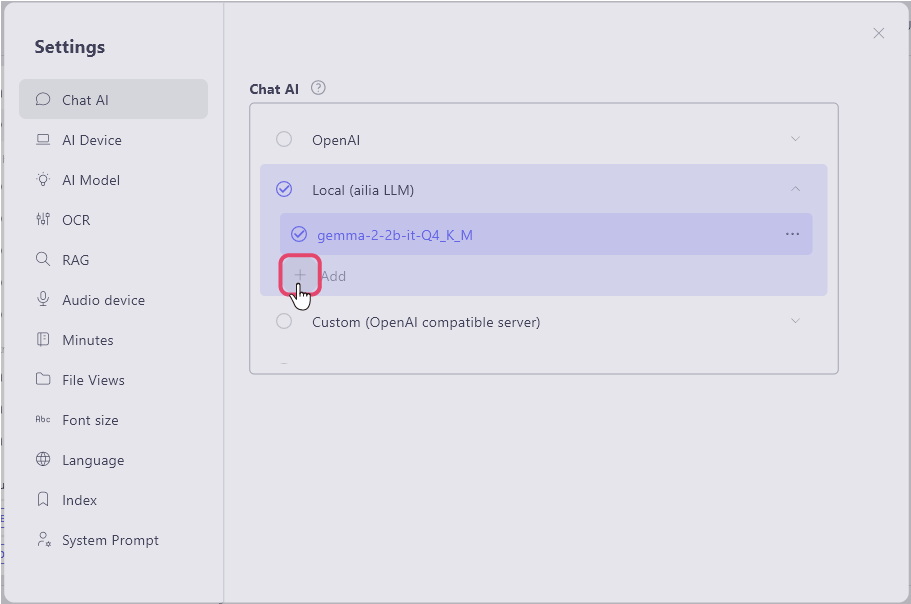
Select the Chat AI item in the settings
 and choose '+ Add' for 'Local (ailiaLLM)'.
and choose '+ Add' for 'Local (ailiaLLM)'.
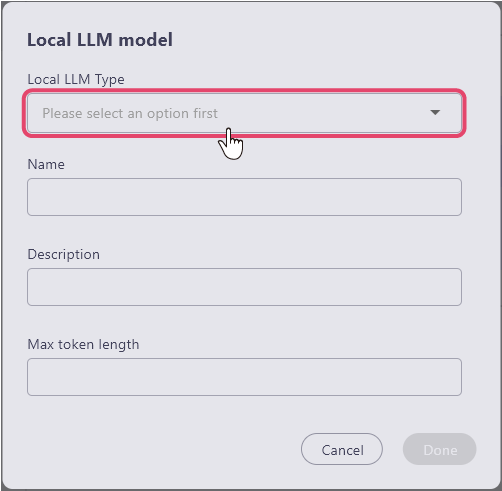
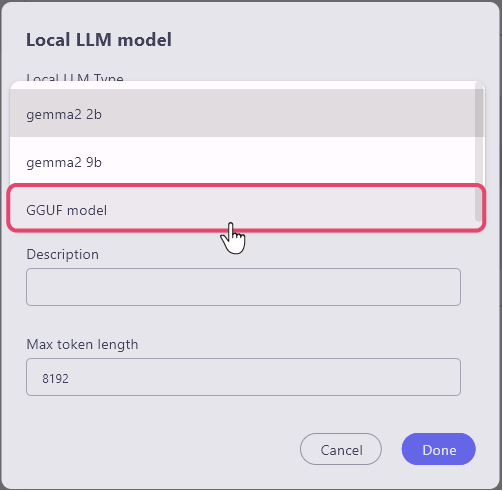
The window for registering the local LLM model will open. First, select the 'Local LLM model type' item.
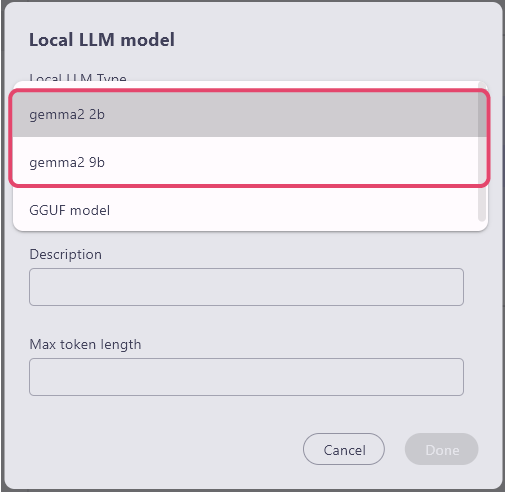
Selecting from the Standard LLM
Simply specify the standard LLM from the 'Local LLM Model Type' item, and you can download the local model.
When you select an LLM, the name and maximum token length are automatically entered.
(Please enter the description item optionally as needed)
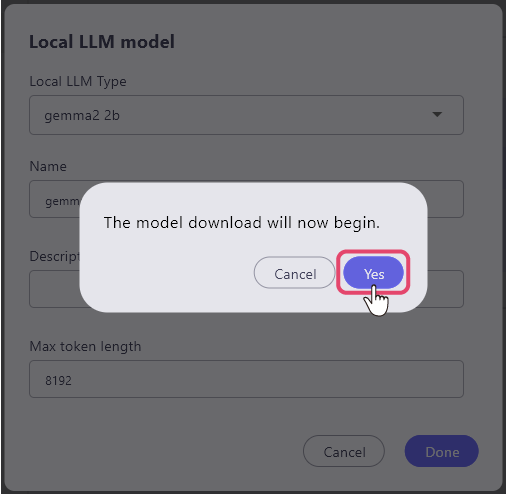
Click 'Done' at the bottom right, and a message window saying 'the model download will now begin.' appears, and if you select 'Yes', the download will begin.
(If you have already selected a downloaded model, this window will not be displayed)
Using GGUF file
By changing the "local LLM Model Type" item to "GGUF model," the "GGUF model path" item will be displayed.
Enter each item.
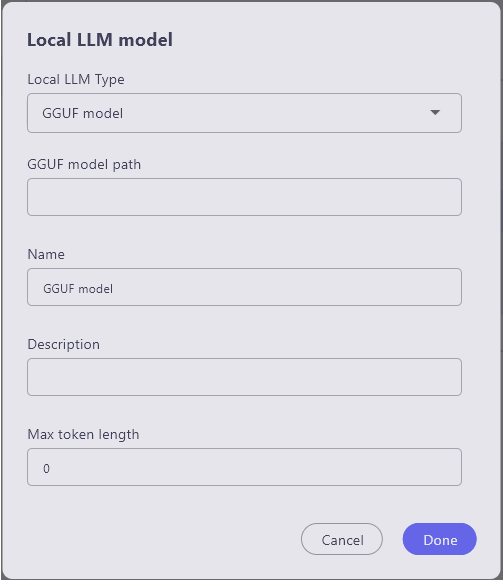
- local LLM Type: Select GGUF model
- GGUF model path: Enter the directory of the GGUF file
- Name: Name of the LLM to use (can be anything as it is only used for UI display)
- Description: Use as a memo if necessary
- Max Token Length: Enter according to the downloaded model