Build Custom LLM with FastChat
Installing FastChat
Install fschat as a Python module on the terminal where you want to set up the server.
pip3 install fschat
Starting the Server
Start vicuna-7b-v1.5 as a ChatGPT API compatible server.
python3 -m fastchat.serve.controller
python3 -m fastchat.serve.model_worker –model-names “vicuna” –model-path lmsys/vicuna-7b-v1.5 –load-8bit
python3 -m fastchat.serve.openai_api_server –-host localhost –-port 8000
Registering Custom LLM in ailia DX Insight
Refer to here for detailed settings.
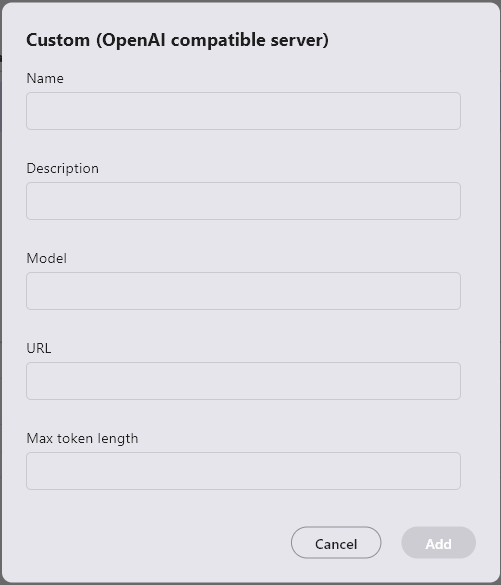
- Name: The name of the LLM to be used (can be anything as it is used only for UI display)
- Description: Use as a memo as needed
- Model: The name of the model specified in the OpenAI compatible API server (gpt-3.5-turbo, etc.)
- URL(*): The IP address and port number issued by the OpenAI compatible API server (e.g., if the server is published as –host 192.168.1.10 –port 8000, use http://192.168.1.10:8000)
- Maximum Token Length: Set the maximum token count supported by the model (4096 or greater, the topK for RAG is determined based on this value)
(*) If not filled, an HTTP connection error will occur.